Modernizing Avida's Data Platform for productivity, testability and developer experience


Data Edge has helped Avida, a specialist in credit cards, consumer loans, as well as financing for small and medium-sized growth companies, address key pain points in their data platform implementation.
Avida operates in a domain where regulatory compliance, credit risk monitoring, and data-driven decision-making are essential for sustainable growth. The company’s data team, embedded within a centralized IT organization, is responsible for delivering clean, reliable datasets used for standardized reporting, advanced analytics, and reverse ETL use cases.
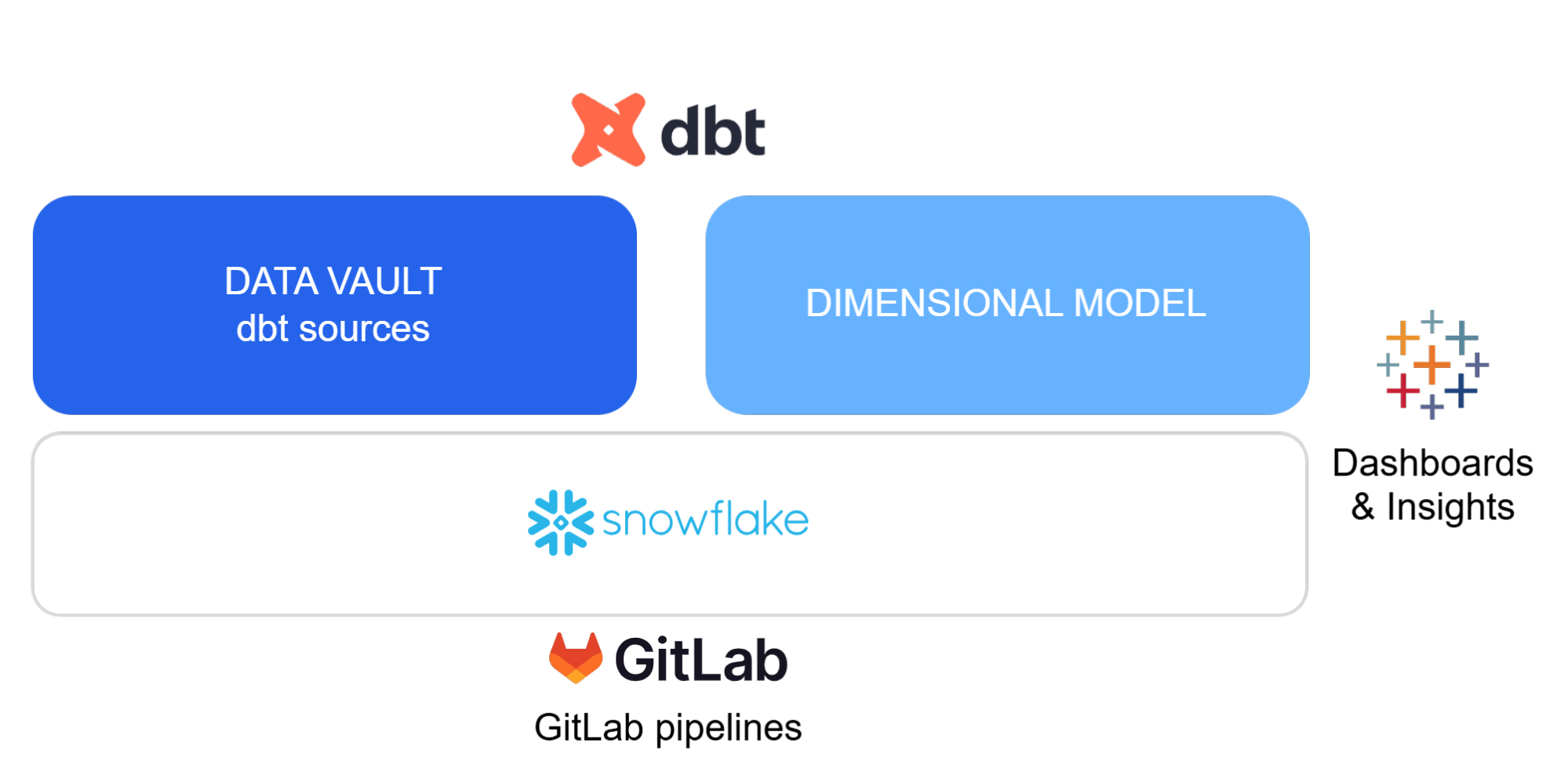
A few years ago, Avida transitioned from an on-premises solution to a cloud-based Data Warehouse built on AWS and Snowflake. This architecture is based on Data Vault modelling, with a consumption layer using Kimball-style dimensional models and data consumed primarily via Tableau. Data transformations are managed using a commercially available cloud ELT tool.
Despite this foundation, a number of challenges gradually emerged:
- Reduced development efficiency and quality: Many key processes remained unautomated, relying on team-specific knowledge and manually maintained documentation, which was often outdated. Team changes led to reduced efficiency and development quality.
- Slow releases: The absence of an automated CI/CD process resulted in slow, error-prone deployments that often required manual hotfixes to solve production issues.
- Increased demand for data literacy: A growing data-driven mindset within the organization highlighted the need for improved data literacy and accessible technical documentation. However, the ELT tool in use stored logic in a non-human readable format that was difficult to interpret, especially for users outside the core development team.
- Diminished trust in data: Implementing data tests was cumbersome, leaving many core datasets without basic quality checks. Consequently, data issues were frequently detected by data consumers, eroding trust in the data.
- Fragmented codebase: Key components were managed outside the DevOps platform and tied to system-specific constraints, complicating version control and deployment.
Improved productivity following design principles
Most of the challenges we faced with the platform could be traced back to the absence of three key design principles. We centered our change approach around these principles, each essential to a modern data platform.
1. Prioritize the developer experience: Eliminate unnecessary manual steps whenever possible, to boost quality, consistency, and speed. Make best practices easy and intuitive to follow.
We consolidated all business logic into dbt, a SQL-based framework that embraces several key software design principles. This enabled us to establish a unified, well established framework, replacing previously scattered components that had kept transformation logic and data definitions separated.
We also introduced an automated CI/CD process based on GitLab pipelines and an indirect promotion branching strategy. This together with the introduction of isolated development environments per developer made it possible for us to speed up the development cycle and increase the number of releases done to production, and at the same time guarantee better quality.
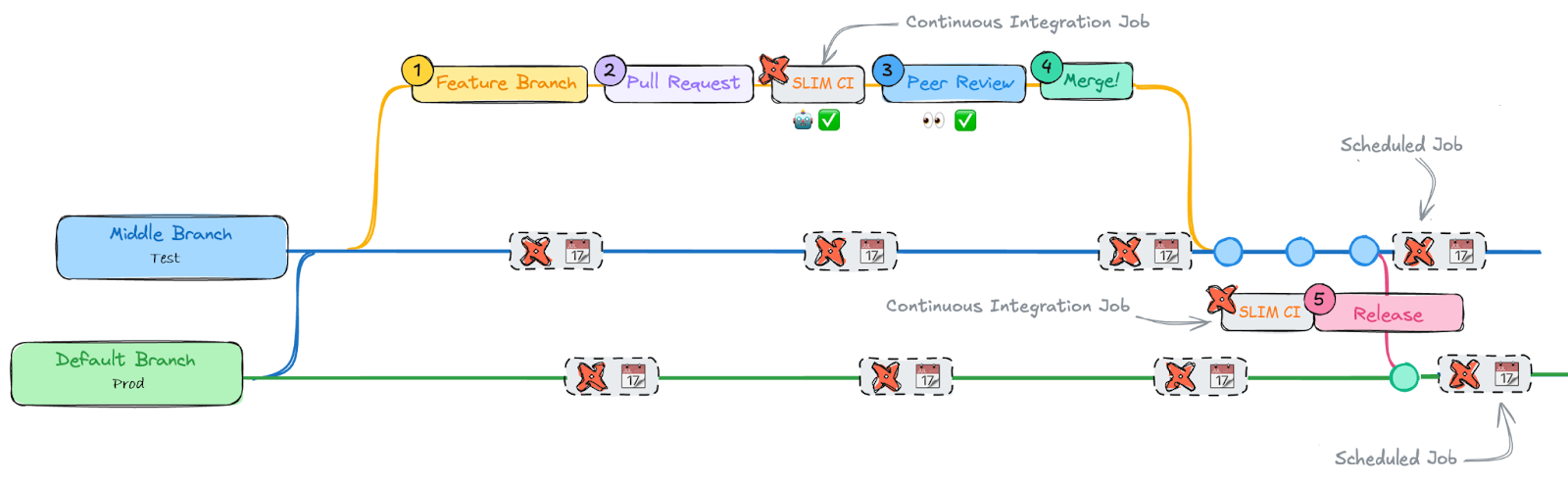
Image adapted from git-branching-strategies-with-dbt
2. Build for testability: Well-tested code and data is easier to onboard, extend, and maintain. Ensure that data validation is a seamless part of the development process.
Both our new CICD process and the ease of adding tests in dbt, quickly added a basic level of data quality to the consumption layer. Thanks to this test coverage, we quickly reduced the number of quality issues reported by data consumers, thereby strengthening trust in the data throughout the organization. Automating these tests and integrating them into the development workflow ensured that data testing became a seamless part of the development process.
3. Design for portability, readability and traceability: Keep your codebase portable by minimizing reliance on proprietary and non-human-readable formats.
We migrated the transformation logic into human-readable dbt code hosted in GitLab. A format that can easily be ported between different platforms and is easy to understand and collaborate around. We also implemented automated releases in GitLab, bundling code, documentation, and release notes. This improved traceability for stakeholders and gave them confidence in the development process.
With the help of the data catalog that dbt provides, consumers were able to better understand our transformation logic, which significantly reduced the number of ad hoc questions the team had to address.
Looking Ahead
This modernization initiative marks just the first iteration in Avida’s journey toward a more scalable, reliable, and developer-friendly data platform. By focusing on automation, transparency, and improving the developer experience, we’ve addressed critical pain points and delivered immediate value to both the data team and business users.
With a solid foundation now in place, we’re expanding these improved ways of working to more teams across Avidas, aiming to promote a more consistent and collaborative approach to working with data company-wide.